L’intégration continue Open Source en .NET – 1/3
17 06 2010Article en 3 parties sur l’intégration continue en technologie .NET à l’aide uniquement d’outils open-source.
Cet article est sorti du tiroir puisqu’il a 2 ans, mais il reste totalement d’actualité.
Origines
On oppose généralement l’aspect industriel du développement à l’artisanal. Pour mieux saisir la signification de ce terme, je vous propose une petite histoire :
Après quatre mois de développement, c’est le grand jour de la livraison. Georges, après avoir testé une dernière fois que son code compile, décide de déployer la version finale du site Intranet de la mairie.La démarche est maitrisée puisque cela fait maintenant une vingtaine de fois qu’il a répété l’opération. Comme à chaque fois, il commence par demander à son collègue sur quels fichiers il a travaillé. La liste connue, il récupère par le réseau ces fichiers, puis tente de compiler le projet. Chance, tout compile. La suite est plus délicate, Georges doit se connecter à distance au serveur, migrer la base de données et insérer les données mis à jour. Vient ensuite la partie copie des fichiers sur le serveur et redémarrage du serveur. A ce moment, si tout va bien, le site devrait être mis à jour. Malheureusement, au premier test, impossible de se logger.
Si cette scène vous rappelle quelque chose, pas d’inquiétude car c’est courant et aujourd’hui de nombreuses sociétés fonctionnent dans ce mode de gestion. Mais l’industrialisation et l’automatisation sont maintenant un but plus facile que jamais à atteindre grace à de nombreux outils. Preuve en est également l’implication de Microsoft sur le thème « Gestion du cycle de vie logiciel » et la fourniture d’une offre complète avec la suite Team System et son serveur Team Foundation Server.
Néamoins pour des raisons de simplicité, nous nous attacherons ici à présenter les concepts de l’intégration continue à l’aide uniquement d’outils open-source.
Concept
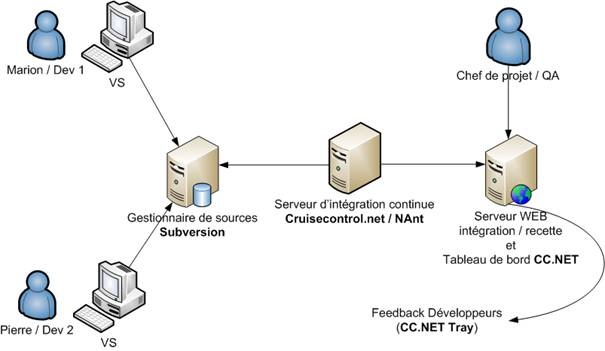
Figure : Schématisation d’une chaîne d’intégration continue
L’intégration continue est un concept qui se base sur l’analogie avec une usine automatisée. Sauf qu’au lieu de constuire des voitures, on construit un logiciel. Cette « usine » est construite sur l’enchainement suivant :
- Un développeur travaille en local. Lorque ses modifications sont terminées, il archive son code sur un serveur gestionnaire de sources.
- A la detection d’un changement (ou suivant une règle temporelle paramétrée), le serveur d’intégration récupère la dernière version des sources et déclenche la contruction (« build ») de la solution.
- En étape facultative mais intéressante, il est possible d’appliquer des métriques et des tests sur la solution et d’en générer des rapports
- Enfin, la solution et le bilan de la construction sont déployés sur un serveur de résultat accessible à l’équipe projet. Dans le cas d’un sous traitance, ce portail peut aussi être mis à la disposition du client pour qu’il puisse constater l’avancement du projet. (Particulièrement utile dans le cadre d’une démarche agile).
Mis en pratique
Après ces concepts théoriques, nous allons nous attaquer à la réalisation de notre chaine d’intégration continue. Afin de garder un ensemble cohérent, nous restreindrons notre programme à une unique classe effectuant une manipulation sur une chaîne de caractères. Cette chaine sera fournie au programme en ligne de commande et le résultat sera affiché à l’écran.
Le programme
Il s’agit d’une classe « ChaineManip » qui contient une méthode « Manip ». La méthode Manip prend 2 strin en paramètre et affiche sur la sortie le résultat de l’opération. Afin de pouvoir être executé directement en ligne de commande, cette classe possède également une méthode Main qui délègue l’appel à ChaineManip.Manip. Voici le code :
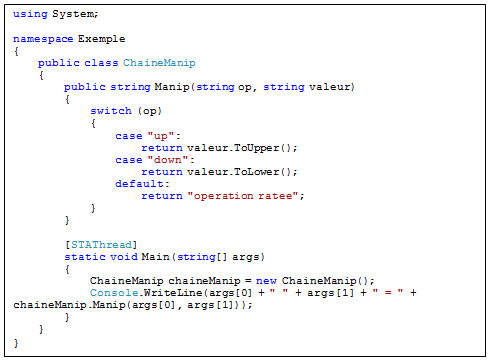
Figure : ChaineManip.cs
Tests unitaires
La démarche d’industrialisation s’accompagne naturellement d’une meilleure gestion des tests unitaires automatisés. Si vous n’avez encore jamais utilisé de framework, je vous invite à découvrir cette méthodologie (http://www.dotnetguru.org/articles/outils/tests/nunit/nunit.htm).
Dans notre cas, c’est le framework Nunit (http://www.nunit.org) que nous allons utiliser.
Pour nous simplifier la tâche et éviter des soucis de compatibilité, nous allons utiliser les DLL fournis dans l’installation de NAnt (installé au chapitre suivant) et donc nous passer d’une installation de NUnit.
Nous allons ainsi créer une classe de test « ChaineManipTest.cs » qui testera l’unique méthode « Manip » de notre classe programme. Sans entrer dans les détails, le code suivant teste le résult de l’appel de la méthode en le comparant avec un résultat attendu.
L’objectif est de compiler le code de notre programme et d’exécuter les tests unitaires dans la continuité. Si un problème est détecté à l’exécution des tests, la construction est stoppée et la release jugée non fiable.
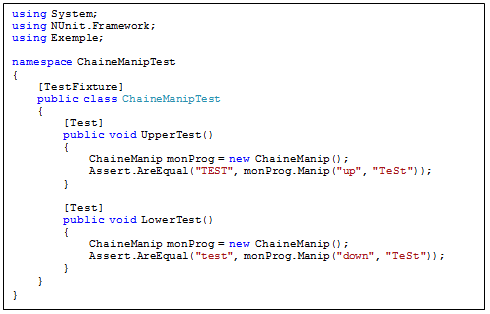
Figure : ChaineManipTest.cs
Contrôle de source
Un gestionnaire de source est la pierre angulaire d’une organisation projet. Si vous n’avez jamais utilisé d’outil de ce genre, je vous incite à vous pencher fortement sur le sujet à travers des articles tels que http://dev.nozav.org/intro_svn.html.
Le principe est donc d’avoir ce serveur à la disposition de l’équipe. Quand un développeur a terminé une modification sur le code, il vérifie que sa modification compile sur son poste puis envoie les sources modifiés sur le serveur. L’outil le plus adapté pour notre chaîne est « Subversion » (http://subversion.tigris.org). Bien qu’en réalité il ne faudrait pas mettre en place de chaine d’intégration continue sans un bon gestionnaire de source, nous allons simplifier notre chaine en utilisant un simple dossier comme « repository » de code.
La suite Partie 2.
Catégories : Dev, DotNet




{kind=link}
{kind=link}
Commentaires récents